작년 고3때 제출했던 exp204로 dothack 2025 컨퍼런스에서 발표를 진행했다.
sechack이랑 나랑 각자 CVE-2023-6931, CVE-2023-5717을 맡았다.
최근에 half 먼저 지급하겠다고 메일이 왔다.
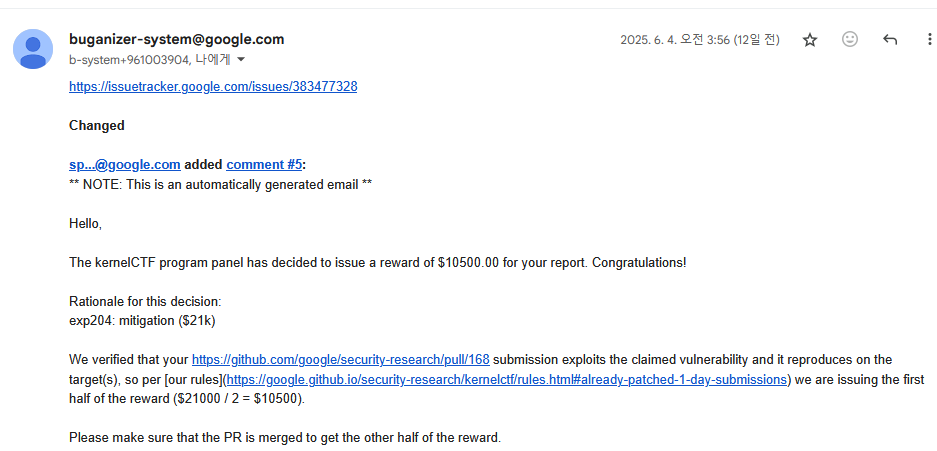
mitigation instance의 경우 exploit reliability 70%를 넘겨야 mitigation 우회로 인정해줘서 안정성 높히는데 많은 시간을 썼다.
익스 자체는 고3때 끝내긴 했었는데, 무슨짓을 해도 70%를 못넘겨서 좀 오래 걸렸다.
카이스트 입학하고 2월달 쯤부터 기숙사에서 익스 안정성 높히는데 시간을 많이 썼다.
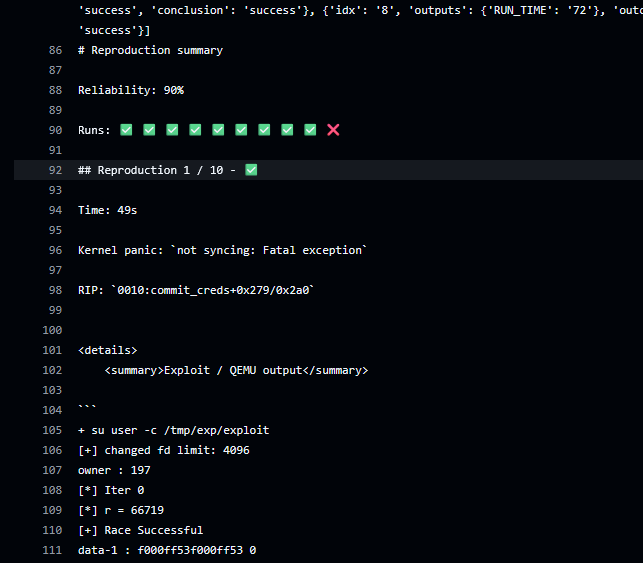
challenges
안정성 높히려고 익스를 많이 고쳤다.
mitigation instance에서 안정성을 박살내는 가장 큰 요인은 perf_event_context_sched_out() 에서 일어나는 최적화 때문이다.
취약점 자체가 race condition 쪽이라 트리거 시도를 많이 해야 한다.
Timer interrupt 받아서 scheduler가 돌면 event group을 sched_in 시키거나 sched_out 시키는데, 이게 exploit 하는 입장에선 상당히 골치 아프다.
취약점 자체가 부모 프로세스와 상속된 자식 프로세스간 events의 구성 불일치와 관련되어 있기에 context 필드가 되게 중요한데, 위 최적화가 막 context를 swap 해버린다.
만약 그룹 소유권을 가진 프로세스가 죽으면 더 이상 다른 어떠한 프로세스도 해당 event group에 수정을 가할 수 없게 되어서 트리거 시도를 더 이상 못하게 된다.
처음에 생각했던 방법은 아주 간단했다.
그냥 무지성으로 프로세스 다 죽이고, 처음부터 다시 이벤트 그룹을 구성하고 트리거를 시도하는 방법이다.
그러면 최적화 신경 안써도 되기 때문에 매우 편하다.
하지만 한번 트리거하는데 기본 몇 시간씩 걸리고, 안정성이 박살난다.
그래서 그 다음으로 생각했던 방법이, cpu pinning을 적절하게 해주면 프로세스 스케쥴링을 어느정도 통제할 수 있으니까 그걸 이용해서 최적화를 우회하는 방법이였다.
기본적으로 해당 최적화는 자식 프로세스와 부모 프로세스의 이벤트들이 같은 그룹내에 속해 있는 경우에만 발생한다.
static void do_perf_sw_event(enum perf_type_id type, u32 event_id,
u64 nr,
struct perf_sample_data *data,
struct pt_regs *regs)
{
struct swevent_htable *swhash = this_cpu_ptr(&swevent_htable);
struct perf_event *event;
struct hlist_head *head;
rcu_read_lock();
head = find_swevent_head_rcu(swhash, type, event_id);
if (!head)
goto end;
hlist_for_each_entry_rcu(event, head, hlist_entry) {
if (perf_swevent_match(event, type, event_id, data, regs))
perf_swevent_event(event, nr, data, regs);
}
end:
rcu_read_unlock();
}
상속된 이벤트들은 무조건 부모 이벤트 계측 cpu랑 같아야 한다.
그래야 실제로 cpu hash table에서 제대로 꺼내와지고 계측된다.
근데 문제는 fork 같은 syscall들을 써서 cpu를 처음부터 완벽하게 고정시킬 수 없다.
cpu 처리 속도가 너무 빨라서 초반에 time slice 만료 이전에 swap 한번 해버리고 막아버려도 별 의미가 없다.
마지막으로 생각했던 방법은 그룹 구성을 다르게 하는 것이다.
잘 생각해보면, context를 swap 하는 것은 애초에 그룹 구성이 같다는 것을 전제로 동작한다.
그래서 이 사실을 다음과 같은 방법으로 이용할 수 있다.
else if (child_pid > 0) { // parent
race_layout_index += 2;
int tmp = perf_event_open(&pe, 0, CPU_A, -1, 0);
close(tmp);
usleep(20000);
kill(child_pid, SIGCONT); // now we pinned the ownership. now child process is allowed to exit.
스케쥴러를 최대한 예측 가능하게 만들려면, 자식 프로세스에서 그룹에 어떠한 수정도 주지 않은 상태에서 SIGSTOP을 raise 해놓고 부모에서 위 코드를 실행하면 된다.
그러면 계속 ctx swap 된다.
race를 트리거하려면 어차피 두 프로세스를 병렬적으로 실행시켜야 하지만, 초반부에만 이렇게 동작하도록 강제해주면 되게 쉽게 소유권을 고정시켜줄 수 있다.
부모 프로세스로 실행 흐름이 돌아왔다는 것은 부모 context가 돌아온 것이니, 그때 바로 더미 이벤트를 만들어서 고정시켜버리면 모든 문제가 해결된다.
해당 방법을 이용해서 속도를 엄청나게 빠르게 개선했고, 안정성도 매우 높게 나오게 만들었다.
사실 최적화쪽 코드를 완벽하게 이해하고 있었으면, 이렇게 돌고 돌아서 익스하진 않았을텐데 처음에 정확하게 구조를 이해하는게 확실히 중요한거 같다.
아래는 컨퍼런스 사진이다.

