SLUB Allocator
Userland에선 ptmalloc2가 있는 반면, Kernelland에선 SLUB이 있다.
초기엔 SLAB Allocator를 사용했지만, 현재 대부분의 배포판은 SLUB을 이용한다.
기존 SLAB allocator의 단점을 개선한 버전이다.
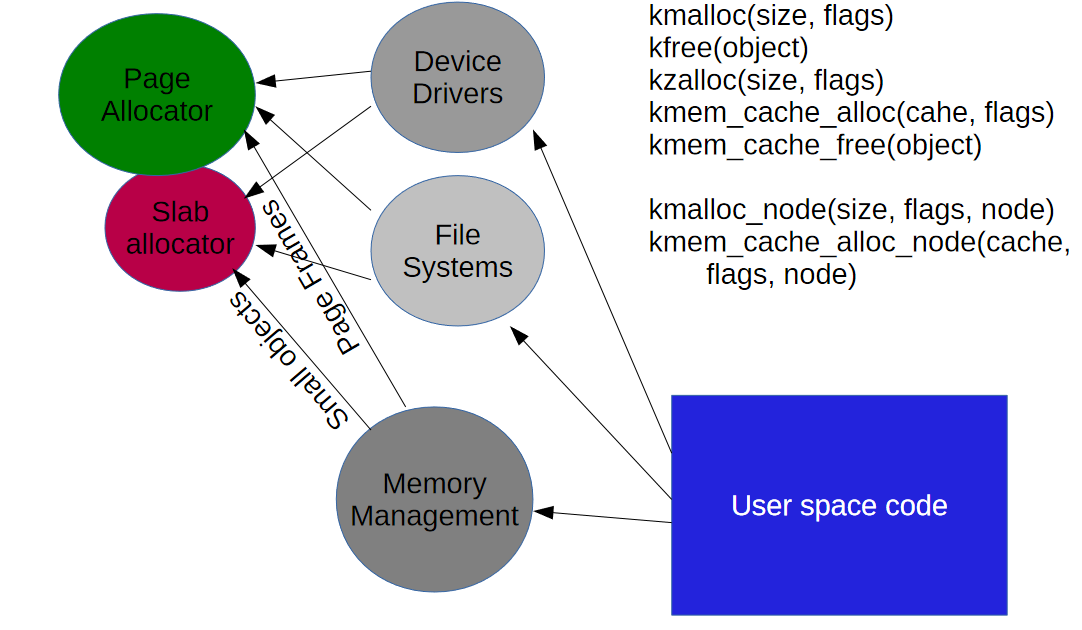
kmem_cache_create로 slab cache를 생성하고 kmem_cache_alloc으로 지정된 slab cache에서 object를 할당한다.
kmem_cache_free로 free하고 kmem_cache_destroy로 slab cache를 제거한다.
kmalloc, kzalloc 같은 함수는 kmalloc-N 캐시에서 적합한 size인 object를 할당한다.
Terms
slab
SLAB allocator랑 다른말이다.
slab cache (= kmem_cache)를 확보하고 관리하는 주체다.
slab cache
msh@raspberrypi:~ $ sudo cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
fuse_request 0 0 144 113 1 : tunables 0 0 0 : slabdata 0 0 0
fuse_inode 0 0 832 19 1 : tunables 0 0 0 : slabdata 0 0 0
kcopyd_job 0 0 3240 20 4 : tunables 0 0 0 : slabdata 0 0 0
ip6-frags 0 0 184 89 1 : tunables 0 0 0 : slabdata 0 0 0
PINGv6 0 0 1216 26 2 : tunables 0 0 0 : slabdata 0 0 0
RAWv6 78 78 1216 26 2 : tunables 0 0 0 : slabdata 3 3 0
UDPv6 96 96 1344 24 2 : tunables 0 0 0 : slabdata 4 4 0
tw_sock_TCPv6 0 0 264 62 1 : tunables 0 0 0 : slabdata 0 0 0
request_sock_TCPv6 0 0 312 52 1 : tunables 0 0 0 : slabdata 0 0 0
TCPv6 108 108 2368 27 4 : tunables 0 0 0 : slabdata 4 4 0
ext4_groupinfo_4k 11303 11303 184 89 1 : tunables 0 0 0 : slabdata 127 127 0
scsi_sense_cache 256 256 128 128 1 : tunables 0 0 0 : slabdata 2 2 0
fscrypt_info 0 0 128 128 1 : tunables 0 0 0 : slabdata 0 0 0
bio-120 640 640 128 128 1 : tunables 0 0 0 : slabdata 5 5 0
mqueue_inode_cache 17 17 960 17 1 : tunables 0 0 0 : slabdata 1 1 0
nfs4_xattr_cache_cache 0 0 2128 30 4 : tunables 0 0 0 : slabdata 0 0 0
nfs_direct_cache 0 0 224 73 1 : tunables 0 0 0 : slabdata 0 0 0
nfs_commit_data 23 23 704 23 1 : tunables 0 0 0 : slabdata 1 1 0
nfs_read_data 36 36 896 18 1 : tunables 0 0 0 : slabdata 2 2 0
nfs_inode_cache 0 0 1072 30 2 : tunables 0 0 0 : slabdata 0 0 0
fat_inode_cache 60 60 784 20 1 : tunables 0 0 0 : slabdata 3 3 0
fat_cache 818 818 40 409 1 : tunables 0 0 0 : slabdata 2 2 0
jbd2_journal_head 680 680 120 136 1 : tunables 0 0 0 : slabdata 5 5 0
jbd2_revoke_table_s 2048 2048 16 1024 1 : tunables 0 0 0 : slabdata 2 2 0
ext4_fc_dentry_update 0 0 96 170 1 : tunables 0 0 0 : slabdata 0 0 0
ext4_inode_cache 11274 11286 1184 27 2 : tunables 0 0 0 : slabdata 418 418 0
ext4_allocation_context 480 480 136 120 1 : tunables 0 0 0 : slabdata 4 4 0
ext4_system_zone 1227 1227 40 409 1 : tunables 0 0 0 : slabdata 3 3 0
ext4_io_end 1024 1024 64 256 1 : tunables 0 0 0 : slabdata 4 4 0
ext4_bio_post_read_ctx 341 341 48 341 1 : tunables 0 0 0 : slabdata 1 1 0
ext4_pending_reservation 2048 2048 32 512 1 : tunables 0 0 0 : slabdata 4 4 0
ext4_extent_status 6119 6135 40 409 1 : tunables 0 0 0 : slabdata 15 15 0
mbcache 1168 1168 56 292 1 : tunables 0 0 0 : slabdata 4 4 0
kioctx 0 0 576 28 1 : tunables 0 0 0 : slabdata 0 0 0
fanotify_fid_event 0 0 72 227 1 : tunables 0 0 0 : slabdata 0 0 0
dnotify_struct 0 0 32 512 1 : tunables 0 0 0 : slabdata 0 0 0
audit_tree_mark 0 0 80 204 1 : tunables 0 0 0 : slabdata 0 0 0
kvm_vcpu 0 0 9680 13 8 : tunables 0 0 0 : slabdata 0 0 0
rpc_inode_cache 23 23 704 23 1 : tunables 0 0 0 : slabdata 1 1 0
UNIX 210 210 1088 30 2 : tunables 0 0 0 : slabdata 7 7 0
ip4-frags 0 0 200 81 1 : tunables 0 0 0 : slabdata 0 0 0
MPTCP 0 0 1920 17 2 : tunables 0 0 0 : slabdata 0 0 0
request_sock_subflow_v4 0 0 384 42 1 : tunables 0 0 0 : slabdata 0 0 0
xfrm_dst_cache 0 0 320 51 1 : tunables 0 0 0 : slabdata 0 0 0
xfrm_state 0 0 768 21 1 : tunables 0 0 0 : slabdata 0 0 0
ip_fib_trie 1364 1364 48 341 1 : tunables 0 0 0 : slabdata 4 4 0
ip_fib_alias 1168 1168 56 292 1 : tunables 0 0 0 : slabdata 4 4 0
PING 0 0 1024 16 1 : tunables 0 0 0 : slabdata 0 0 0
RAW 16 16 1024 16 1 : tunables 0 0 0 : slabdata 1 1 0
커널에는 이런식으로 미리 여러 슬랩캐시들이 확보되어있다.
주로 프로세스 생성에 자주 사용되는 task struct, cred 들도 미리 확보되어있다.
slab page
slab object 할당을 위해 Buddy system에서 할당받은 order-n 단위의 page.
slab object
slab cache에서 관리하는 object.
Buddy system
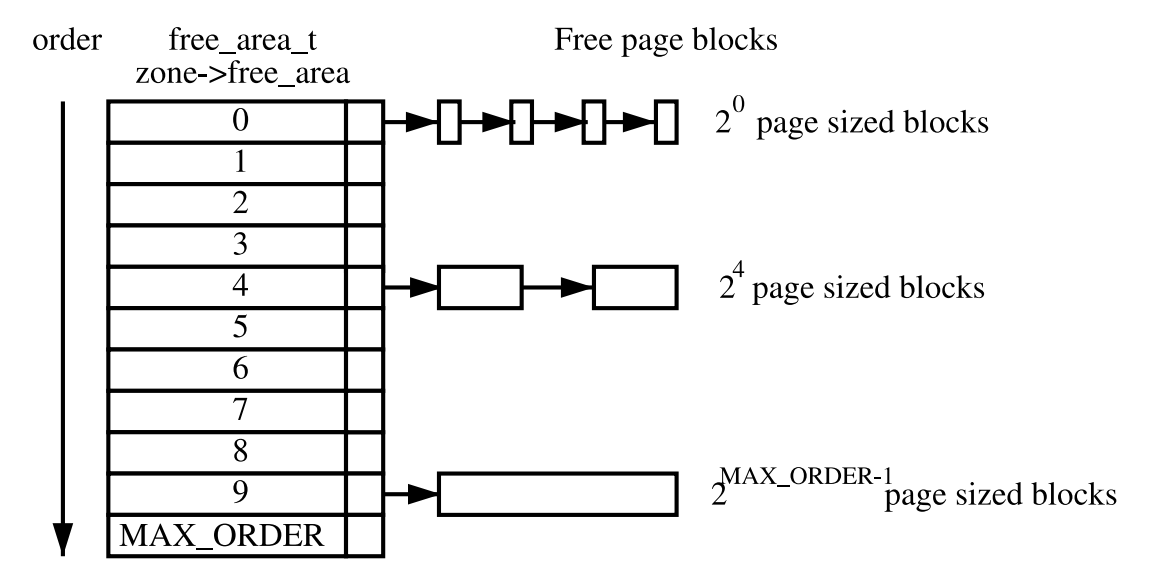
외부 단편화를 줄이기위해 4k 사이즈의 page 단위로 할당한다.
slab allocator는 반대로 buddy system에서 받은 page를 잘 관리해서 내부 단편화를 줄이기 위해 사용된다.
Internal Structure
SLAB vs SLUB
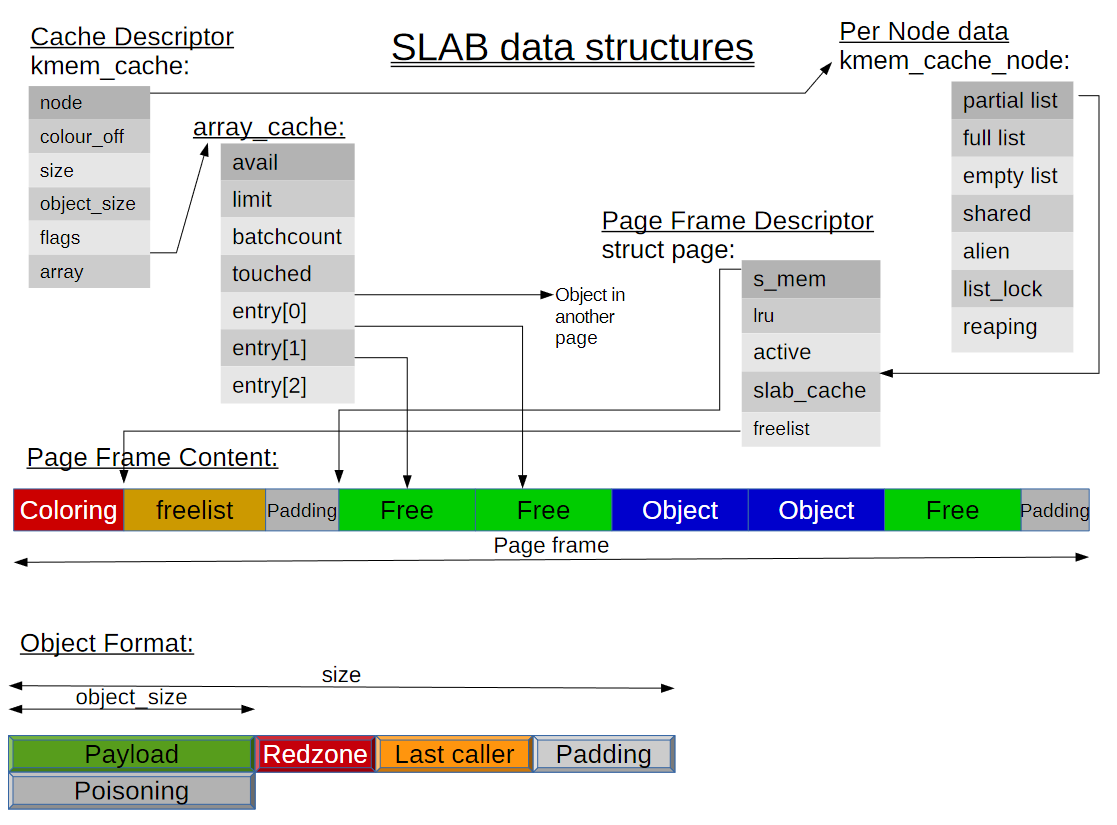
SLAB allocator의 구조다.
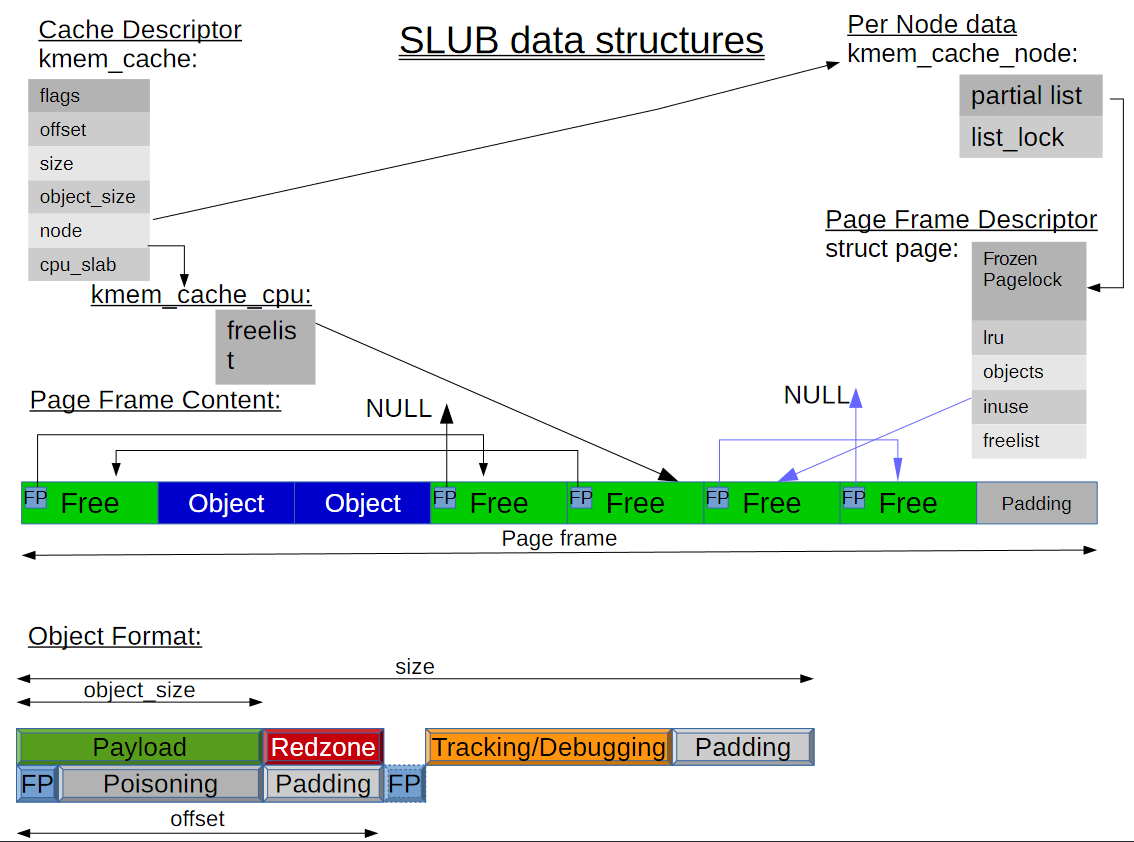
SLUB allocator의 구조다.
struct page는 struct slab으로 구조체 이름이 변경되었다.
cpu 별 cache를 둠으로써 lock less한 처리가 가능해졌다.
왜 이런 구조가 되었는지 이해하려면 NUMA 아키텍쳐에 대해서 알아보아야한다.
NUMA (Non-uniform memory access)
한 개 이상의 CPU가 동일한 시스템 자원을 사용하는 시스템을 SMP (Symmetric Multi-Processors) 환경이라고 부른다.
SMP 환경에서는 동일한 자원에 대한 병목이 발생한다.
특정 프로세서가 하나의 주요 자원을 선점하고 lock을 걸어놓으면 당연하게 지연이 발생한다.
멀티 프로세서 시스템에서의 메모리 설계 아키텍쳐를 NUMA라고 부른다.
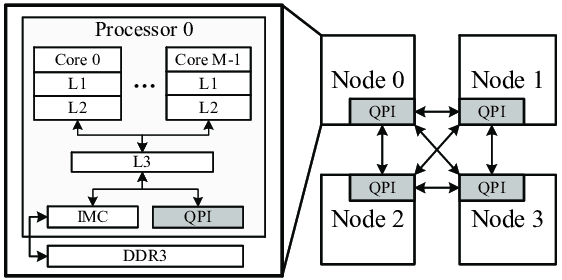
위와 같은 구조다.
Node를 만들어서 구분해놓은 것을 볼 수 있다.
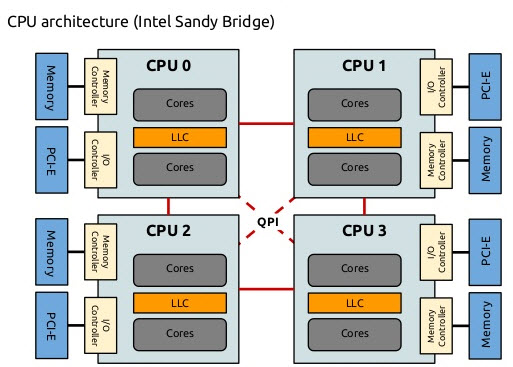
CPU에 메모리 버스를 하나씩 물려놓고 각자 memory를 붙여놨다.
local memory에 access 하는건 빠르지만, 상대적으로 다른 node의 메모리 access는 느리다는게 특징이다.
실제로 물리적인 cpu의 성능도 올라가고 core, thread 수도 올라가고 하이퍼쓰레딩같은 기술도 나오다보니 이러한 아키텍쳐가 많이 활용된다.
SLUB allocator도 예외는 아니다.
kmem_cache
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
struct work_struct kobj_remove_work;
#endif
#ifdef CONFIG_MEMCG
struct memcg_cache_params memcg_params;
int max_attr_size; /* for propagation, maximum size of a stored attr */
#ifdef CONFIG_SYSFS
struct kset *memcg_kset;
#endif
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
struct kmem_cache_cpu __percpu *cpu_slab은 cpu별 슬랩 캐시를 관리하는 구조체다.
struct kmem_cache_node *node[MAX_NUMNODES]는 앞서 설명한 NUMA node별로 관리하기 위한 구조체이다.
unsigned int *random_seq은 Freelist randomization이 적용되면서 추가되었다.
Flags
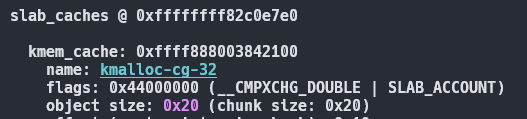


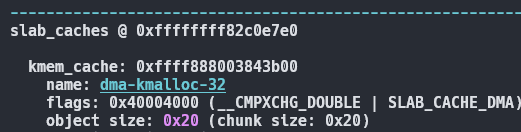
이런식으로 slab cache마다 플래그가 다르다.
rcl은 자주 reclaim 하는 inode같은 객체들을 위해 이용된다.
cg는 가변 크기 객체에 대해서 사용이 많이된다.
dma는 dma 관련 메모리 할당에 이용된다
그중 SLAB_ACCOUNT는 GFP_KERNEL_ACCOUNT와 독립된 캐시를 이용한다.
중간에 패치로 동일한 캐시를 이용한적이 있었지만 다시 독립된 캐시로 변경되었다.
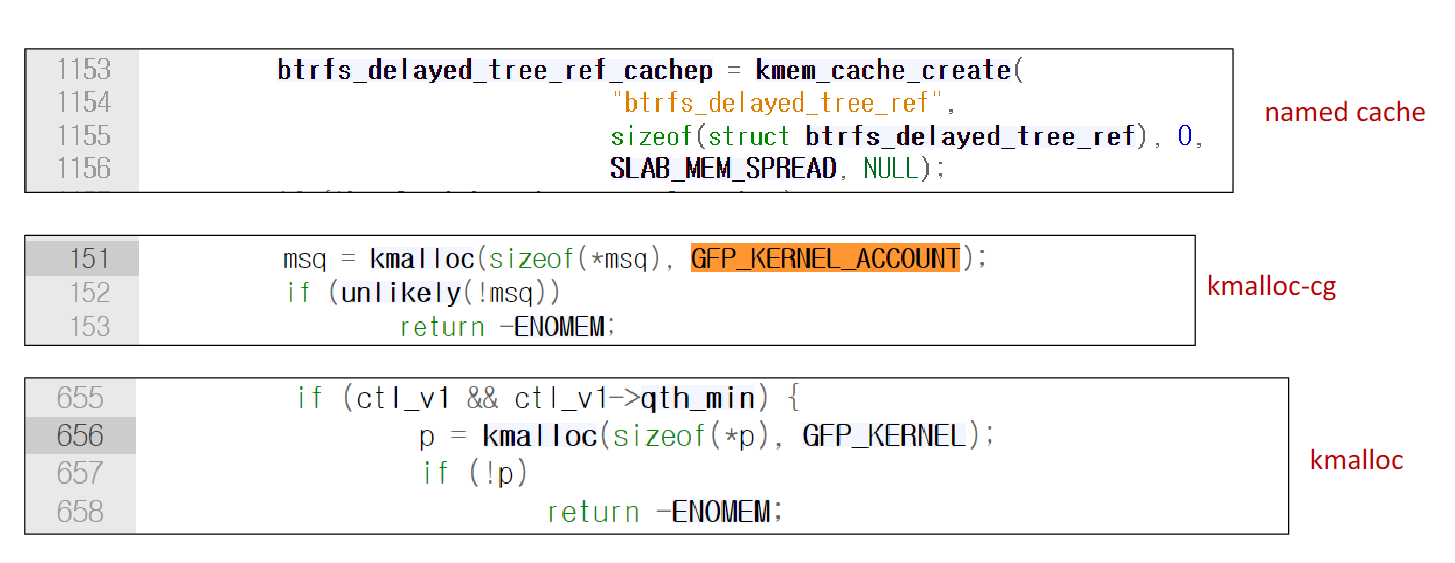
위와 같이 이용된다.
Freelist randomization
#ifdef CONFIG_SLAB_FREELIST_RANDOM
/* Pre-initialize the random sequence cache */
static int init_cache_random_seq(struct kmem_cache *s)
{
unsigned int count = oo_objects(s->oo);
int err;
/* Bailout if already initialised */
if (s->random_seq)
return 0;
err = cache_random_seq_create(s, count, GFP_KERNEL);
if (err) {
pr_err("SLUB: Unable to initialize free list for %s\n",
s->name);
return err;
}
/* Transform to an offset on the set of pages */
if (s->random_seq) {
unsigned int i;
for (i = 0; i < count; i++)
s->random_seq[i] *= s->size;
}
return 0;
}
/* Get the next entry on the pre-computed freelist randomized */
static void *next_freelist_entry(struct kmem_cache *s, struct slab *slab,
unsigned long *pos, void *start,
unsigned long page_limit,
unsigned long freelist_count)
{
unsigned int idx;
/*
* If the target page allocation failed, the number of objects on the
* page might be smaller than the usual size defined by the cache.
*/
do {
idx = s->random_seq[*pos];
*pos += 1;
if (*pos >= freelist_count)
*pos = 0;
} while (unlikely(idx >= page_limit));
return (char *)start + idx;
}
freelist가 랜덤화되면서 객체의 순차적 할당이나 재할당을 어렵게 만든다.
kmem_cache_cpu
#ifndef CONFIG_SLUB_TINY
/*
* When changing the layout, make sure freelist and tid are still compatible
* with this_cpu_cmpxchg_double() alignment requirements.
*/
struct kmem_cache_cpu {
union {
struct {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
};
freelist_aba_t freelist_tid;
};
struct slab *slab; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct slab *partial; /* Partially allocated frozen slabs */
#endif
local_lock_t lock; /* Protects the fields above */
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
#endif /* CONFIG_SLUB_TINY */
freelist는 cpu별 free objects의 리스트이다.
slab은 cpu에서 할당에 사용중인 슬랩이다.
원래 이름은 struct page였는데, kernel 5.17부터 struct slab으로 명칭이 변경되었다.
partial은 해당 page내 일부 object가 cpu에서 사용중인 경우 partial list로 관리된다.
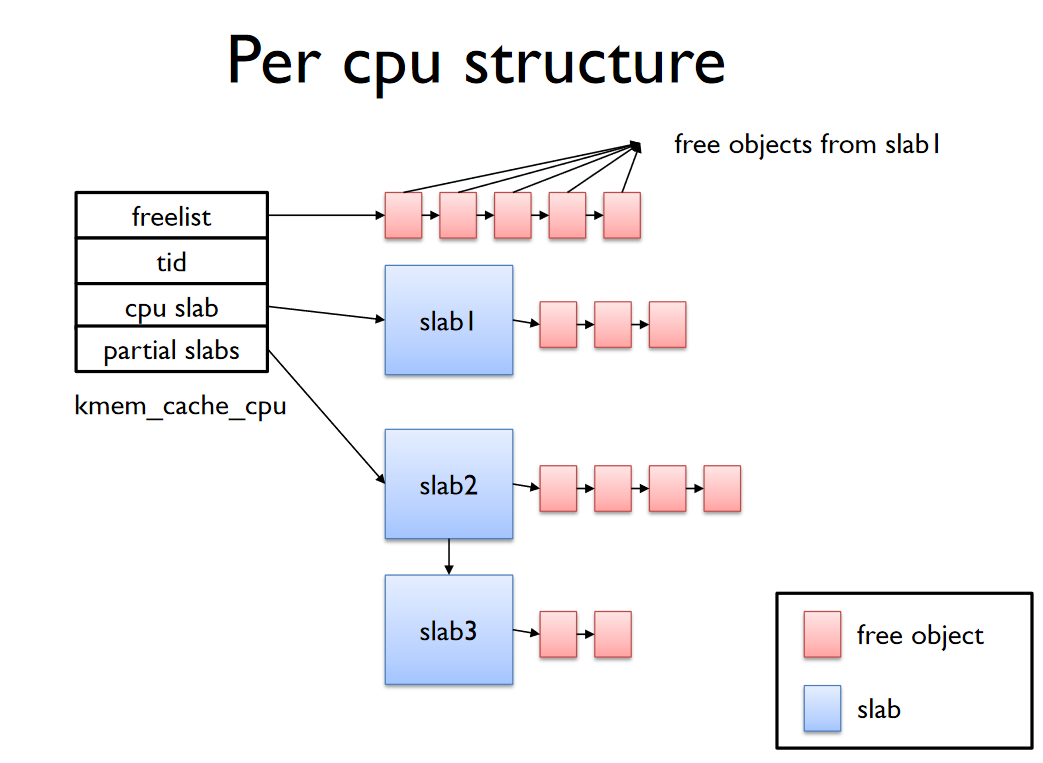
이런식으로 현재 할당에 이용할 slab엔 하나의 slab page가 링크되고, partial slabs에는 대기중인 slab page들이 링크되어있다.
cpu slab의 page의 freelist와 percpu struct의 freelist는 같다.
하지만 다른 NUMA node에서 remote free 할때 실제 slab struct의 freelist와 약간 달라질 수 있다.
struct slab
/* Reuses the bits in struct page */
struct slab {
unsigned long __page_flags;
#if defined(CONFIG_SLAB)
struct kmem_cache *slab_cache;
union {
struct {
struct list_head slab_list;
void *freelist; /* array of free object indexes */
void *s_mem; /* first object */
};
struct rcu_head rcu_head;
};
unsigned int active;
#elif defined(CONFIG_SLUB)
struct kmem_cache *slab_cache;
union {
struct {
union {
struct list_head slab_list;
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct {
struct slab *next;
int slabs; /* Nr of slabs left */
};
#endif
};
/* Double-word boundary */
union {
struct {
void *freelist; /* first free object */
union {
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
};
};
#ifdef system_has_freelist_aba
freelist_aba_t freelist_counter;
#endif
};
};
struct rcu_head rcu_head;
};
unsigned int __unused;
#else
#error "Unexpected slab allocator configured"
#endif
atomic_t __page_refcount;
#ifdef CONFIG_MEMCG
unsigned long memcg_data;
#endif
};
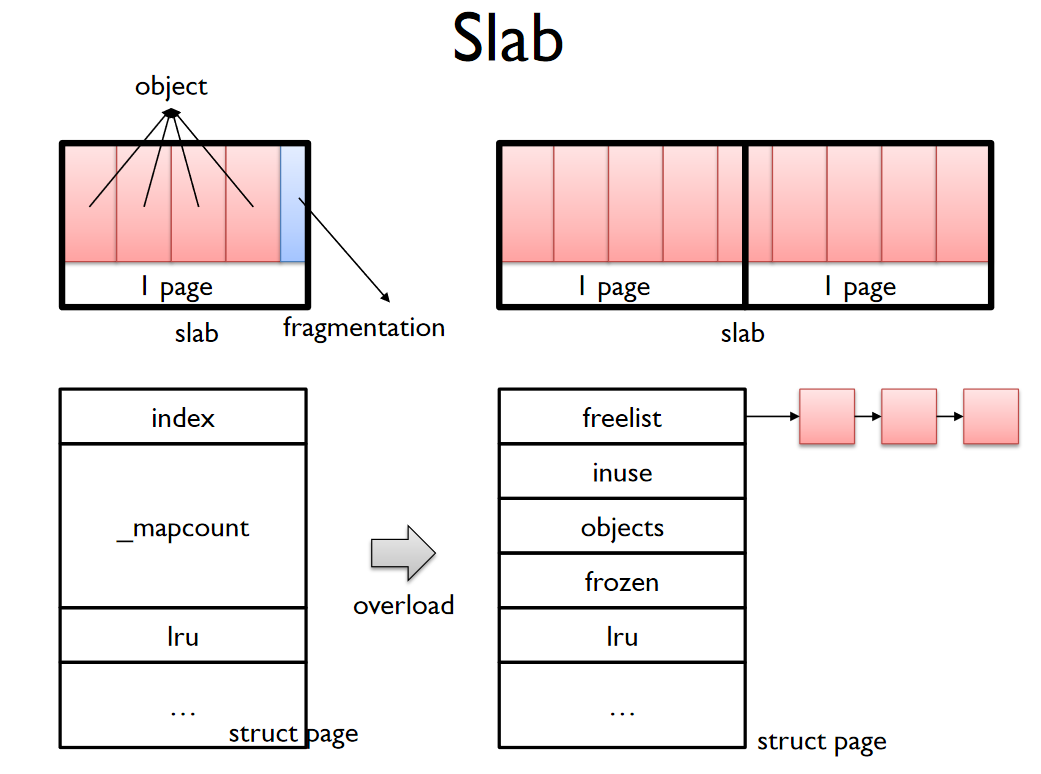
struct page에서 이름이 바뀌었다.
percpu에서도 있지만, slab page 구조체에서도 freelist가 있다.
이 둘을 이용해서 할당 & 해제를 좀 더 효율적으로 진행한다.
이에 대해선 Allocation 관련 설명을 하면서 후술한다.
kmem_cache_node
struct kmem_cache_node {
#ifdef CONFIG_SLAB
raw_spinlock_t list_lock;
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
spinlock_t list_lock;
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
spinlock_t list_lock은 node에 동시접근 방지하기 위한 lock이다.
그리고 struct list_head partial은 node별로 관리되는 partial page list이다.
Allocation
정리하자면, kmem_cache_cpu는 CPU 별로 각자의 슬랩 페이지를 주고 관리하게 한다.
그리고 kmem_cache_cpu struct의 freelist는 할당에 이용되는 slab에 대한 freelist이다.
lockless하게 할당과 해제를 진행하게 된다.
근데 struct slab에서도 freelist가 존재했다.
cpu -> freelist와 cpu -> slab -> freelist는 차이가 있다.
전자는 현재 CPU가 관리하며 free시 추가된다.
후자는 현재 CPU가 관리하는 slab page에 속한 object를 remote CPU가 free시에 리스트에 추가된다.
이러한 remote cpu, 즉 전담 cpu가 아닌 경우엔 항상 free만 가능하다.
frozen page는 list management에서 제외되는 페이지를 뜻한다.
freeze한 cpu만이 list operation을 수행하며, object를 freelist에서 뽑아오는 연산등을 할 수 있다.
frozen page여도 다른 cpu가 object를 freelist를 넣을 수는 있다.
이러한 frozen page에서 cpu -> freelist가 가리키는 free object들과 in-use object들은 cpu -> page.inuse의 값과 같으며 remote cpu가 free 할때만 감소한다.
즉 현재 CPU가 컨트롤하고 있는 object 개수만 inuse로 취급한다는 뜻이다.
앞서 remote cpu는 전담 cpu의 slab object에 대한 free만 가능하다는 사실과 일맥상통한다.
Fast-Path
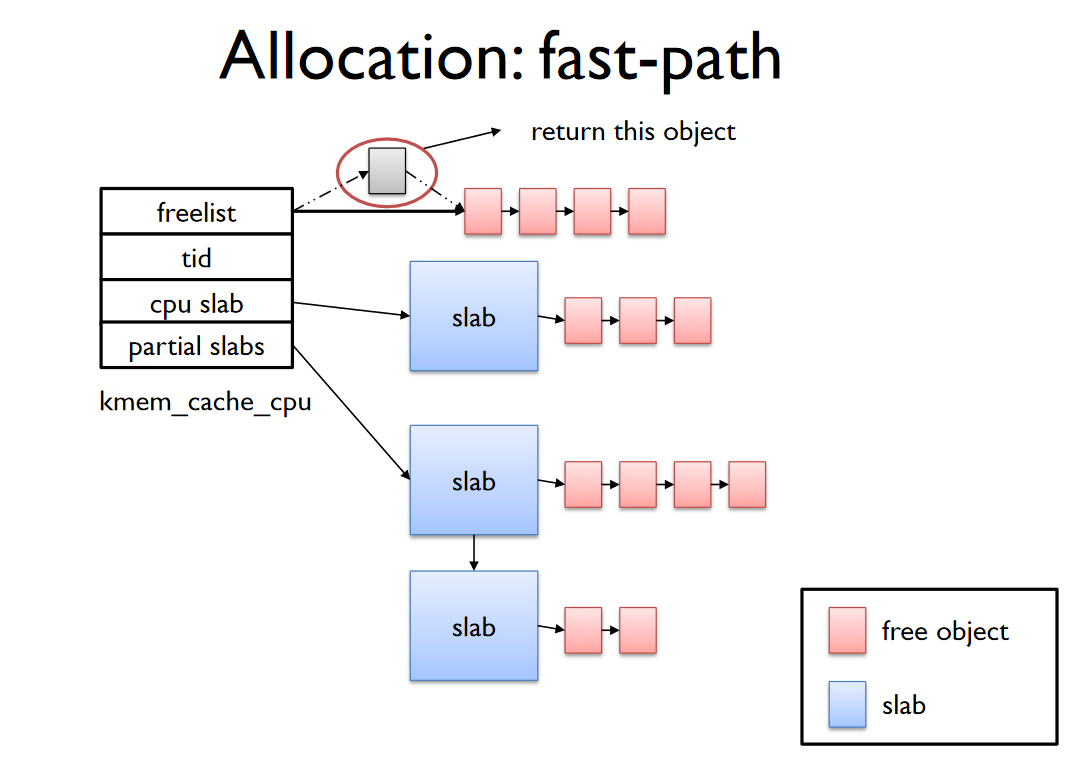
- cpu -> freelist에서 object 할당한다.
Slow-Path 1, 2
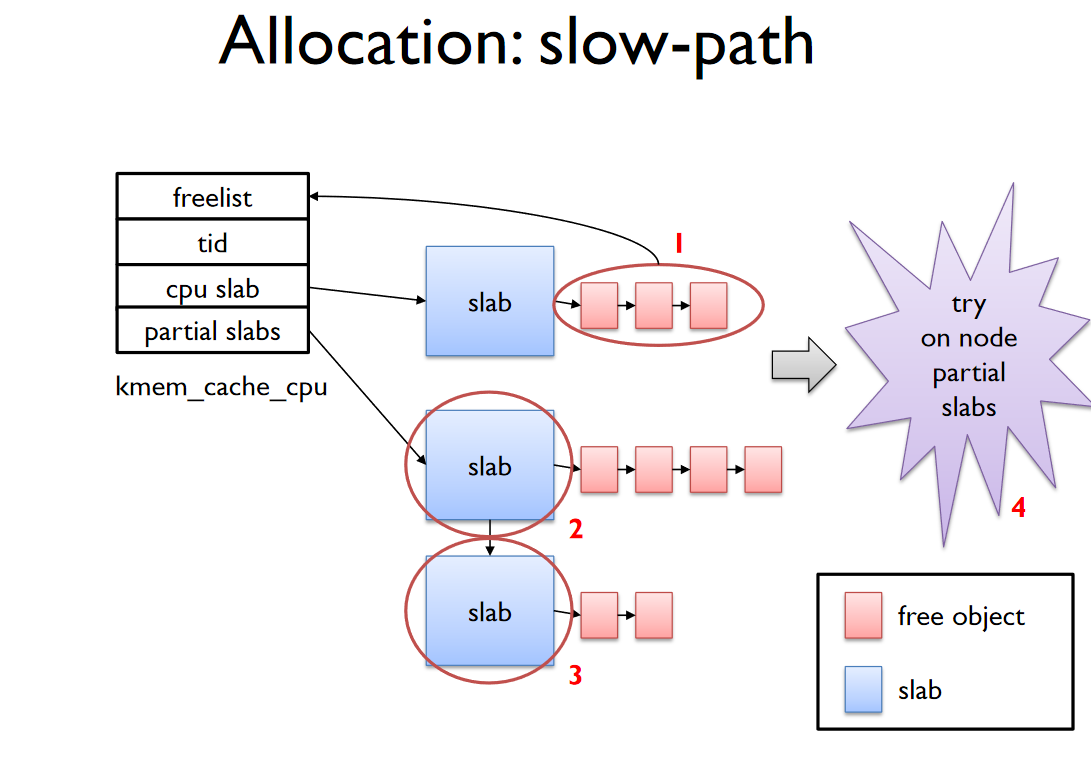
Slow-Path 1
- cpu -> slab에 freelist를 cpu -> freelist로 옮긴다.
- cpu -> freelist에서 object를 할당한다
Slow-Path 2
- cpu -> partial를 cpu -> page로 옮긴다.
- cpu -> page -> freelist를 cpu -> freelist로 옮긴다.
- cpu -> freelist에서 object를 할당한다.
Slow-Path 3, 4
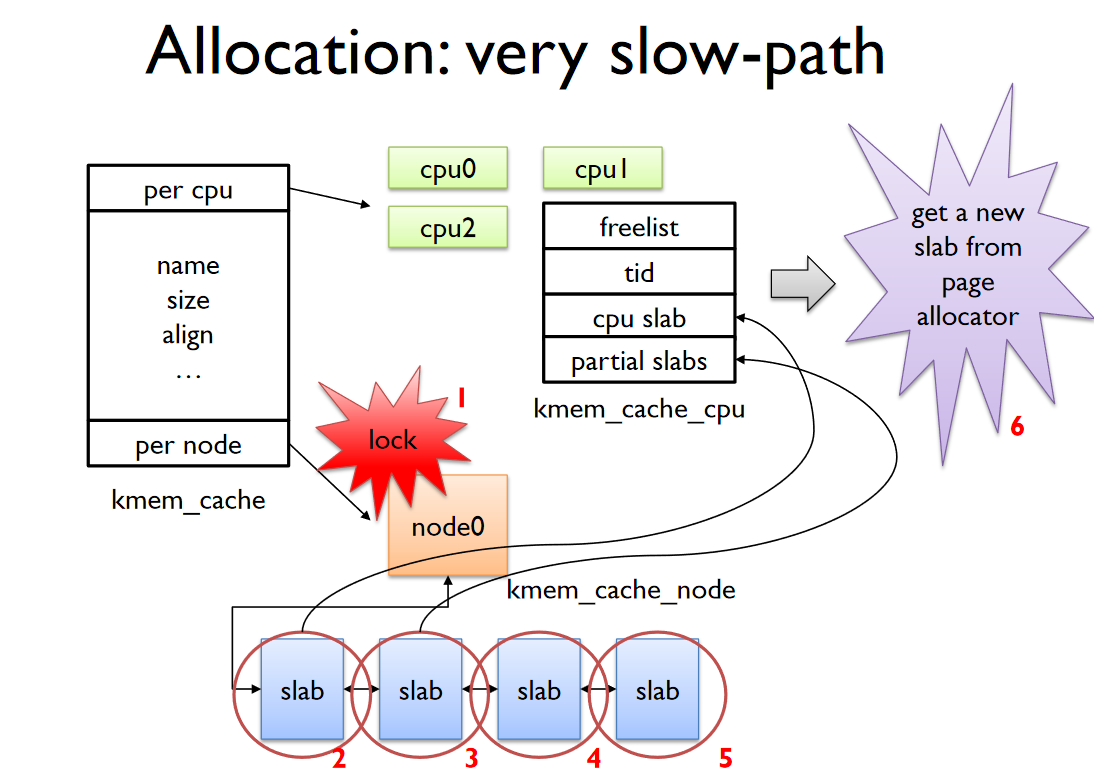
Slow-Path 3
이번엔 slab_cache -> cpu가 아니라 slab_cache -> node 이다.
- node -> partial를 freeze
freeze 하는 이유는 아주 당연하지만 node의 동시 접근 때문이다. - node -> partial를 탐색하다가 page를 cpu -> slab으로 옮긴다.
- cpu -> slab -> freelist를 cpu -> freelist로 옮긴다.
- node -> partial의 slab page 일부를 cpu ->partial로 옮긴다.
moved partial_slabs > s->cpu_partial_slabs / 2
속한 node의 partial list가 비었으면 인접한 node도 탐색한다.
Slow-Path 4
- Buddy System으로부터 신규 slab page를 할당한다.
신규 page는 모든 object가 freelist에 존재한다. - new slab을 cpu -> slab로 옮긴다.
- cpu -> freelist로도 옮긴다.
Deallocation
할당과 비슷하게 fast, slow path가 있다.
Fast-Path
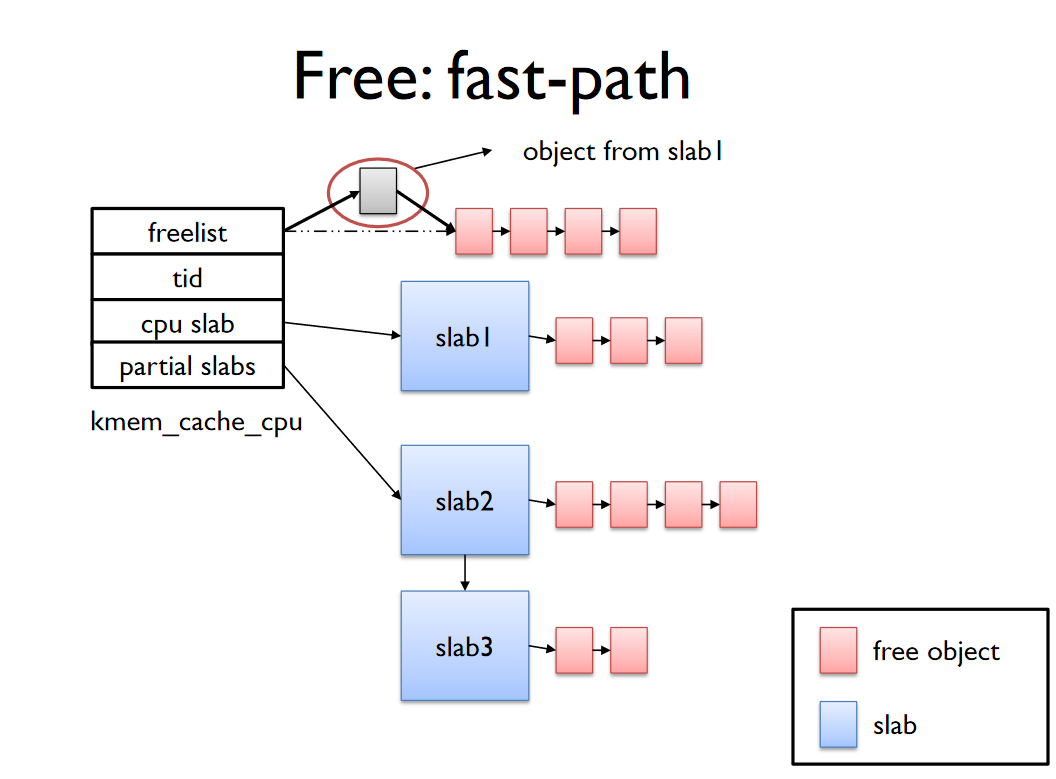
frozen page에 대해서 percpu의 freelist에 바로 반환한다.
Slow-Path
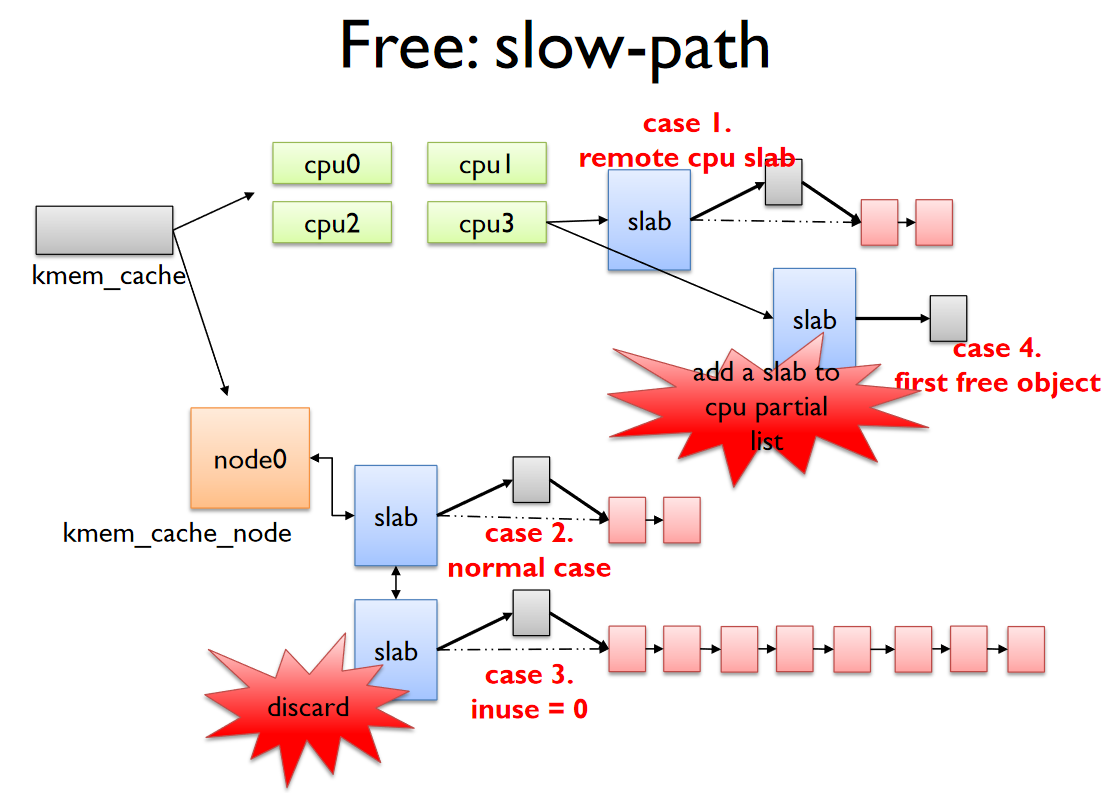
오브젝트가 속한 slab page freelist에 반환한다.
여러 케이스들이 있다.
- remote cpu가 다른 cpu slab을 free해서 리턴한다.
- node의 partial에 리턴한다.
- inuse가 0이면, 관할 cpu가 더이상 효율적으로 이용하지 못한다는 의미이므로 node로 옮긴다. 근데 이때 min_partial 보다 크거나 같아지면 buddy system에 다시 리턴한다.
- node partial이 아니고 모든 객체가 할당된 상태이며 frozen 상태가 아니면 cpu partial에 추가한다.
마지막 부분은 아직 잘 모르겠다.
Optimization
From: Christoph Lameter <cl@linux.com>
To: Tejun Heo <tj@kernel.org>
Cc: akpm@linux-foundation.org
Cc: Pekka Enberg <penberg@cs.helsinki.fi>
Cc: linux-kernel@vger.kernel.org
Cc: Eric Dumazet <eric.dumazet@gmail.com>
Cc: "H. Peter Anvin" <hpa@zytor.com>
Cc: Mathieu Desnoyers <mathieu.desnoyers@efficios.com>
Subject: [[cpuops cmpxchg double V2 4/4] Lockless (and preemptless) fastpaths for slub](https://lore.kernel.org/lkml/20110106204526.977812009@linux.com/#r)
Date: Thu, 06 Jan 2011 14:45:17 -0600 [[thread overview]](https://lore.kernel.org/lkml/20110106204526.977812009@linux.com/#r)
Message-ID: <20110106204526.977812009@linux.com> ([raw](https://lore.kernel.org/lkml/20110106204526.977812009@linux.com/raw))
In-Reply-To: 20110106204513.669098445@linux.com
[[-- /blog/Linux_kernel_SLUB_Allocator #1: cpuops_double_slub_fastpath --]
[-- Type: text/plain, Size: 12414 bytes --]](https://lore.kernel.org/lkml/20110106204526.977812009@linux.com/1-cpuops_double_slub_fastpath)
Use the this_cpu_cmpxchg_double functionality to implement a lockless
allocation algorithm on arches that support fast this_cpu_ops.
Each of the per cpu pointers is paired with a transaction id that ensures
that updates of the per cpu information can only occur in sequence on
a certain cpu.
A transaction id is a "long" integer that is comprised of an event number
and the cpu number. The event number is incremented for every change to the
per cpu state. The cmpxchg instruction can therefore verify for an
update that nothing else has interfered and that we are updating the percpu'
structure for the processor where we initially picked up the information
and that we are also currently on that processor.
So there is no need even to disable preemption.
Test results show that the fastpath cycle count is reduced by up to ~ 40%
(alloc/free test goes from ~140 cycles down to ~80). The slowpath for kfree
adds a few cycles.
Sadly this does nothing for the slowpath which is where the main issues with
performance in slub are but the best case performance rises significantly.
(For that see the more complex slub patches that require cmpxchg_double)
Kmalloc: alloc/free test
Before:
10000 times kmalloc(8)/kfree -> 134 cycles
10000 times kmalloc(16)/kfree -> 152 cycles
10000 times kmalloc(32)/kfree -> 144 cycles
10000 times kmalloc(64)/kfree -> 142 cycles
10000 times kmalloc(128)/kfree -> 142 cycles
10000 times kmalloc(256)/kfree -> 132 cycles
10000 times kmalloc(512)/kfree -> 132 cycles
10000 times kmalloc(1024)/kfree -> 135 cycles
10000 times kmalloc(2048)/kfree -> 135 cycles
10000 times kmalloc(4096)/kfree -> 135 cycles
10000 times kmalloc(8192)/kfree -> 144 cycles
10000 times kmalloc(16384)/kfree -> 754 cycles
After:
10000 times kmalloc(8)/kfree -> 78 cycles
10000 times kmalloc(16)/kfree -> 78 cycles
10000 times kmalloc(32)/kfree -> 82 cycles
10000 times kmalloc(64)/kfree -> 88 cycles
10000 times kmalloc(128)/kfree -> 79 cycles
10000 times kmalloc(256)/kfree -> 79 cycles
10000 times kmalloc(512)/kfree -> 85 cycles
10000 times kmalloc(1024)/kfree -> 82 cycles
10000 times kmalloc(2048)/kfree -> 82 cycles
10000 times kmalloc(4096)/kfree -> 85 cycles
10000 times kmalloc(8192)/kfree -> 82 cycles
10000 times kmalloc(16384)/kfree -> 706 cycles
Kmalloc: Repeatedly allocate then free test
Before:
10000 times kmalloc(8) -> 211 cycles kfree -> 113 cycles
10000 times kmalloc(16) -> 174 cycles kfree -> 115 cycles
10000 times kmalloc(32) -> 235 cycles kfree -> 129 cycles
10000 times kmalloc(64) -> 222 cycles kfree -> 120 cycles
10000 times kmalloc(128) -> 343 cycles kfree -> 139 cycles
10000 times kmalloc(256) -> 827 cycles kfree -> 147 cycles
10000 times kmalloc(512) -> 1048 cycles kfree -> 272 cycles
10000 times kmalloc(1024) -> 2043 cycles kfree -> 528 cycles
10000 times kmalloc(2048) -> 4002 cycles kfree -> 571 cycles
10000 times kmalloc(4096) -> 7740 cycles kfree -> 628 cycles
10000 times kmalloc(8192) -> 8062 cycles kfree -> 850 cycles
10000 times kmalloc(16384) -> 8895 cycles kfree -> 1249 cycles
After:
10000 times kmalloc(8) -> 190 cycles kfree -> 129 cycles
10000 times kmalloc(16) -> 76 cycles kfree -> 123 cycles
10000 times kmalloc(32) -> 126 cycles kfree -> 124 cycles
10000 times kmalloc(64) -> 181 cycles kfree -> 128 cycles
10000 times kmalloc(128) -> 310 cycles kfree -> 140 cycles
10000 times kmalloc(256) -> 809 cycles kfree -> 165 cycles
10000 times kmalloc(512) -> 1005 cycles kfree -> 269 cycles
10000 times kmalloc(1024) -> 1999 cycles kfree -> 527 cycles
10000 times kmalloc(2048) -> 3967 cycles kfree -> 570 cycles
10000 times kmalloc(4096) -> 7658 cycles kfree -> 637 cycles
10000 times kmalloc(8192) -> 8111 cycles kfree -> 859 cycles
10000 times kmalloc(16384) -> 8791 cycles kfree -> 1173 cycles
Signed-off-by: Christoph Lameter <cl@linux.com>
---
include/linux/slub_def.h | 5 -
mm/slub.c | 205 ++++++++++++++++++++++++++++++++++++++++++++++-
2 files changed, 207 insertions(+), 3 deletions(-)
찾아보니 위와 같은 패치를 찾을 수 있었다.
percpu의 tid는 percpu update마다 증가되며 순차적인 업데이트를 보장한다.
중간에 interrupt로 인해 실행흐름이 넘어갈때 똑같이 percpu에 접근해서 할당을 하거나 하면 순차적인 업데이트를 보장하지 못한다.
왜냐하면 allocation request가 왔을때 freelist를 읽었는데, 이때 실행흐름이 새로운 allocation request로 넘어가면 분명 다른 두가지 요청인데 같은 메모리를 리턴하게 될 수도 있기 때문이다.
이를 방지하기 위해서 원래는 interrupt disable 했었다.
근데 만약 cmpxchg double을 지원하는 아키텍쳐에서 이를 이용하면 단순히 tid에 대한 검증과 리턴을 하나의 명령내에서 처리가 가능하다.
당연히 interrupt를 쓰지 않아도 되며, tid를 모든 allocation request가 순차적이라는 것을 보장할 수 있게 되었다.
또한 free시에도 lockless하게 구현할 수 있게 되었다.
원래 freelist를 가져가서 lock 걸고 list에서 뽑고 counter를 줄였는데, cmpxchg double로 그때 그때 counter 비교해서 다른 cpu가 counter 건들면 retry하면 된다.
Debugging
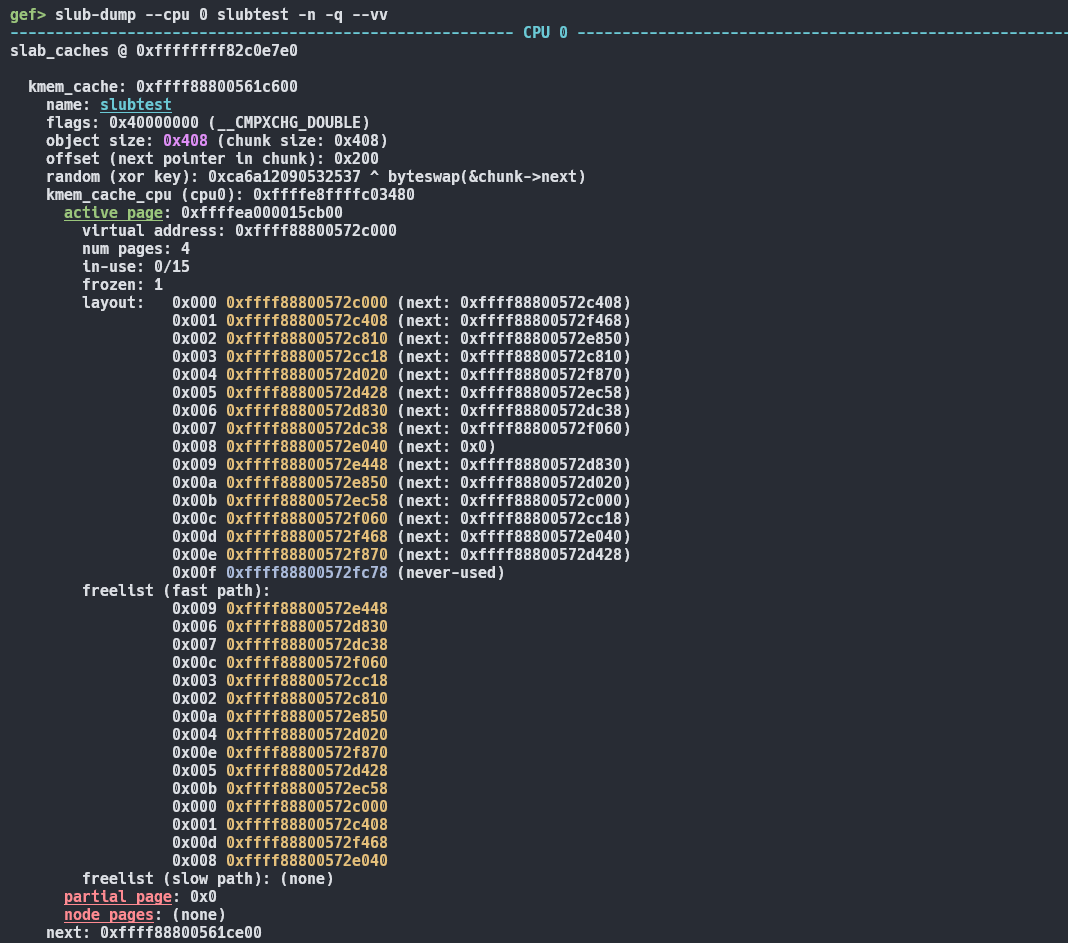
직접 디버깅해보면, 슬랩 캐시도 보이고 random도 보인다.
5.19 기준으로 random 값이 있었고 청크의 next가 mangling 되어있었다.
나머지는 앞에서 살펴봤던 구조와 같았다.
percpu를 확인해보면

이런식으로 freelist가 존재한다.

정상적으로 첫번째 slab object가 리턴되는것을 확인할 수 있다.